Indian Philosophies as Reinforcement Learning
Indian Philosophies as Reinforcement Learning
Reinforcement Learning (RL) provides a powerful framework for understanding intelligence and decision-making. At its core, RL models an agent interacting with an environment, taking actions to maximize cumulative reward. This paradigm turns out to be surprisingly applicable to various domains, including, as I’ve been pondering lately, Indian philosophical systems.
The RL Setup
Let’s start with a quick refresher on RL. The basic setup involves:
- An agent
- An environment
- A set of possible actions
- State observations
- A reward signal
The agent’s goal is to learn a policy that maximizes expected cumulative reward over time. This framework is remarkably general and can model a wide range of situations.
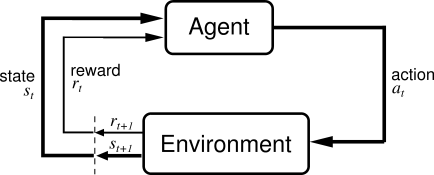
The Agent-Environment Interface in Reinforcement Learning
Indian Philosophy: The Big Picture
Now, let’s turn to Indian philosophy. While diverse, many schools share some common themes:
- Atman: Individual consciousness
- Brahman: Supreme or universal consciousness
- Samsara: The phenomenal world of experience and rebirth
The central question often revolves around the relationship between these entities. How does individual consciousness relate to the universal? What’s the nature of our experienced reality?
An RL Perspective on Advaita Vedanta
Let’s start with Advaita Vedanta, one of the most influential schools of Indian philosophy. In the RL framework, we might map it like this:
- Atman (individual consciousness) → Agent
- Samsara (phenomenal world) → Environment
- Brahman (supreme consciousness) → The “true” nature of reality

Adi Shankara, the propounder of Advaita Vedanta
The key insight of Advaita is that Atman and Brahman are ultimately identical. In RL terms, this is like saying the agent and the entirety of the system (agent + environment) are one and the same. The apparent duality – the sense of being a separate agent in an environment – is considered an illusion (maya). It’s as if the universal consciousness is playing a cosmic game of RL with itself, creating the appearance of separate agents and an environment.
Visistadvaita: Qualified Non-Dualism
Moving on to Visistadvaita, proposed by Ramanuja, we can model it as:
- Atman (individual consciousness) → Agent
- Samsara (phenomenal world) → Environment
- Brahman (supreme consciousness) → A specific, named entity (e.g., Vishnu)

Ramanujacharya, the propounder of Visistadvaita
In this view, the multiplicity of agents and the environment occurs due to “ego” - a failure to cooperate with other agents while being misled by small rewards within the environment. It’s like an RL scenario where agents are optimizing for local rewards, missing the bigger picture of global optimization. The key difference from Advaita is that while Atman is part of Brahman, it maintains some level of distinctness. In RL terms, it’s as if the agents are sub-components of a larger system, each with their own local reward functions, but ultimately part of a greater whole.
Dvaita: Dualism
Dvaita, proposed by Madhva, takes a different approach:
- Atman (individual consciousness) → Distinct agent
- Samsara (phenomenal world) → Distinct environment
- Brahman (supreme consciousness) → Separate supreme agent creating the environment
 Madhvacharya, the propounder of Dvaita
Madhvacharya, the propounder of Dvaita
In this view, the agent, environment, and supreme agent are indeed separate. It’s akin to a multi-agent RL system where one “super-agent” (Brahman) creates and maintains the environment for other agents (Atman) to operate in. This perspective aligns well with hierarchical RL frameworks, where higher-level agents can shape the environment or reward structures for lower-level agents.
Buddhism: A Different Approach
Buddhism, while not typically categorized with the above systems, offers an interesting contrast:
- Rejects the existence of a supreme agent (no Brahman)
- Focuses on the agent’s experience and decision-making process
- Posits that the optimal policy is to detach from the reward function itself

Gautama Buddha, the founder of Buddhism
In RL terms, Buddhism suggests that the root of suffering (suboptimal outcomes) lies in the reward function itself. The path to enlightenment could be seen as learning to operate without being driven by the conventional reward signal. This is a fascinating inversion of the standard RL objective. Instead of maximizing cumulative reward, the goal becomes to transcend the very notion of reward-seeking behavior.